 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLM-Guided Experience Replay
Feb 02, 2026Recent advances in Large Language Models (LLMs) and Vision-Language Models (VLMs) have enabled powerful semantic and multimodal reasoning capabilities, creating new opportunities to enhance sample efficiency, high-level planning, and interpretability in reinforcement learning (RL). While prior work has integrated LLMs and VLMs into various components of RL, the replay buffer, a core component for storing and reusing experiences, remains unexplored. We propose addressing this gap by leveraging VLMs to guide the prioritization of experiences in the replay buffer. Our key idea is to use a frozen, pre-trained VLM (requiring no fine-tuning) as an automated evaluator to identify and prioritize promising sub-trajectories from the agent's experiences. Across scenarios, including game-playing and robotics, spanning both discrete and continuous domains, agents trained with our proposed prioritization method achieve 11-52% higher average success rates and improve sample efficiency by 19-45% compared to previous approaches. https://esharony.me/projects/vlm-rb/
Optimal Sample Complexity for Single Time-Scale Actor-Critic with Momentum
Feb 02, 2026We establish an optimal sample complexity of $O(ε^{-2})$ for obtaining an $ε$-optimal global policy using a single-timescale actor-critic (AC) algorithm in infinite-horizon discounted Markov decision processes (MDPs) with finite state-action spaces, improving upon the prior state of the art of $O(ε^{-3})$. Our approach applies STORM (STOchastic Recursive Momentum) to reduce variance in the critic updates. However, because samples are drawn from a nonstationary occupancy measure induced by the evolving policy, variance reduction via STORM alone is insufficient. To address this challenge, we maintain a buffer of small fraction of recent samples and uniformly sample from it for each critic update. Importantly, these mechanisms are compatible with existing deep learning architectures and require only minor modifications, without compromising practical applicability.
Spectral Bellman Method: Unifying Representation and Exploration in RL
Jul 17, 2025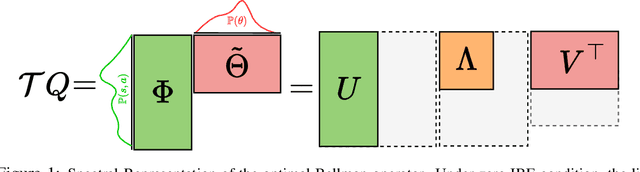
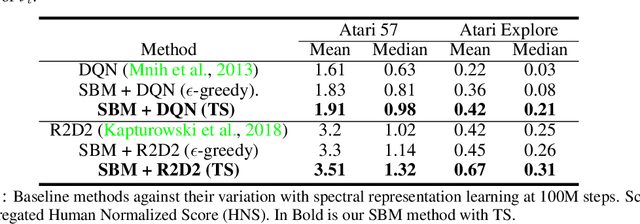

The effect of representation has been demonstrated in reinforcement learning, from both theoretical and empirical successes. However, the existing representation learning mainly induced from model learning aspects, misaligning with our RL tasks. This work introduces Spectral Bellman Representation, a novel framework derived from the Inherent Bellman Error (IBE) condition, which aligns with the fundamental structure of Bellman updates across a space of possible value functions, therefore, directly towards value-based RL. Our key insight is the discovery of a fundamental spectral relationship: under the zero-IBE condition, the transformation of a distribution of value functions by the Bellman operator is intrinsically linked to the feature covariance structure. This spectral connection yields a new, theoretically-grounded objective for learning state-action features that inherently capture this Bellman-aligned covariance. Our method requires a simple modification to existing algorithms. We demonstrate that our learned representations enable structured exploration, by aligning feature covariance with Bellman dynamics, and improve overall performance, particularly in challenging hard-exploration and long-horizon credit assignment tasks. Our framework naturally extends to powerful multi-step Bellman operators, further broadening its impact. Spectral Bellman Representation offers a principled and effective path toward learning more powerful and structurally sound representations for value-based reinforcement learning.
State Entropy Regularization for Robust Reinforcement Learning
Jun 08, 2025



State entropy regularization has empirically shown better exploration and sample complexity in reinforcement learning (RL). However, its theoretical guarantees have not been studied. In this paper, we show that state entropy regularization improves robustness to structured and spatially correlated perturbations. These types of variation are common in transfer learning but often overlooked by standard robust RL methods, which typically focus on small, uncorrelated changes. We provide a comprehensive characterization of these robustness properties, including formal guarantees under reward and transition uncertainty, as well as settings where the method performs poorly. Much of our analysis contrasts state entropy with the widely used policy entropy regularization, highlighting their different benefits. Finally, from a practical standpoint, we illustrate that compared with policy entropy, the robustness advantages of state entropy are more sensitive to the number of rollouts used for policy evaluation.
Policy Gradient with Tree Search: Avoiding Local Optimas through Lookahead
Jun 08, 2025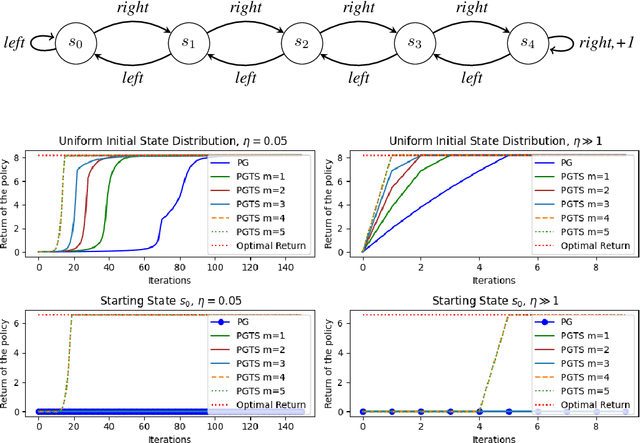
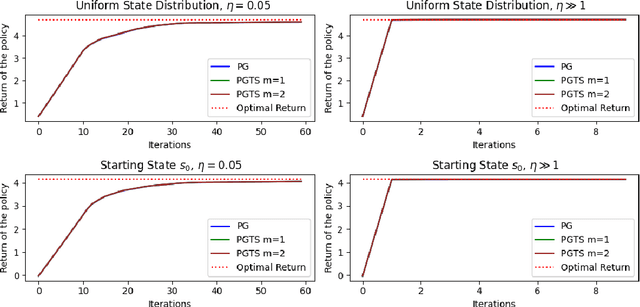

Classical policy gradient (PG) methods in reinforcement learning frequently converge to suboptimal local optima, a challenge exacerbated in large or complex environments. This work investigates Policy Gradient with Tree Search (PGTS), an approach that integrates an $m$-step lookahead mechanism to enhance policy optimization. We provide theoretical analysis demonstrating that increasing the tree search depth $m$-monotonically reduces the set of undesirable stationary points and, consequently, improves the worst-case performance of any resulting stationary policy. Critically, our analysis accommodates practical scenarios where policy updates are restricted to states visited by the current policy, rather than requiring updates across the entire state space. Empirical evaluations on diverse MDP structures, including Ladder, Tightrope, and Gridworld environments, illustrate PGTS's ability to exhibit "farsightedness," navigate challenging reward landscapes, escape local traps where standard PG fails, and achieve superior solutions.
Policy Optimized Text-to-Image Pipeline Design
May 27, 2025Text-to-image generation has evolved beyond single monolithic models to complex multi-component pipelines. These combine fine-tuned generators, adapters, upscaling blocks and even editing steps, leading to significant improvements in image quality. However, their effective design requires substantial expertise. Recent approaches have shown promise in automating this process through large language models (LLMs), but they suffer from two critical limitations: extensive computational requirements from generating images with hundreds of predefined pipelines, and poor generalization beyond memorized training examples. We introduce a novel reinforcement learning-based framework that addresses these inefficiencies. Our approach first trains an ensemble of reward models capable of predicting image quality scores directly from prompt-workflow combinations, eliminating the need for costly image generation during training. We then implement a two-phase training strategy: initial workflow vocabulary training followed by GRPO-based optimization that guides the model toward higher-performing regions of the workflow space. Additionally, we incorporate a classifier-free guidance based enhancement technique that extrapolates along the path between the initial and GRPO-tuned models, further improving output quality. We validate our approach through a set of comparisons, showing that it can successfully create new flows with greater diversity and lead to superior image quality compared to existing baselines.
Adversarial Bandit over Bandits: Hierarchical Bandits for Online Configuration Management
May 25, 2025Motivated by dynamic parameter optimization in finite, but large action (configurations) spaces, this work studies the nonstochastic multi-armed bandit (MAB) problem in metric action spaces with oblivious Lipschitz adversaries. We propose ABoB, a hierarchical Adversarial Bandit over Bandits algorithm that can use state-of-the-art existing "flat" algorithms, but additionally clusters similar configurations to exploit local structures and adapt to changing environments. We prove that in the worst-case scenario, such clustering approach cannot hurt too much and ABoB guarantees a standard worst-case regret bound of $O\left(k^{\frac{1}{2}}T^{\frac{1}{2}}\right)$, where $T$ is the number of rounds and $k$ is the number of arms, matching the traditional flat approach. However, under favorable conditions related to the algorithm properties, clusters properties, and certain Lipschitz conditions, the regret bound can be improved to $O\left(k^{\frac{1}{4}}T^{\frac{1}{2}}\right)$. Simulations and experiments on a real storage system demonstrate that ABoB, using standard algorithms like EXP3 and Tsallis-INF, achieves lower regret and faster convergence than the flat method, up to 50% improvement in known previous setups, nonstochastic and stochastic, as well as in our settings.
Representative Action Selection for Large Action-Space Meta-Bandits
May 23, 2025We study the problem of selecting a subset from a large action space shared by a family of bandits, with the goal of achieving performance nearly matching that of using the full action space. We assume that similar actions tend to have related payoffs, modeled by a Gaussian process. To exploit this structure, we propose a simple epsilon-net algorithm to select a representative subset. We provide theoretical guarantees for its performance and compare it empirically to Thompson Sampling and Upper Confidence Bound.
Accelerating Vehicle Routing via AI-Initialized Genetic Algorithms
Apr 08, 2025Vehicle Routing Problems (VRP) are an extension of the Traveling Salesperson Problem and are a fundamental NP-hard challenge in combinatorial optimization. Solving VRP in real-time at large scale has become critical in numerous applications, from growing markets like last-mile delivery to emerging use-cases like interactive logistics planning. Such applications involve solving similar problem instances repeatedly, yet current state-of-the-art solvers treat each instance on its own without leveraging previous examples. We introduce a novel optimization framework that uses a reinforcement learning agent - trained on prior instances - to quickly generate initial solutions, which are then further optimized by genetic algorithms. Our framework, Evolutionary Algorithm with Reinforcement Learning Initialization (EARLI), consistently outperforms current state-of-the-art solvers across various time scales. For example, EARLI handles vehicle routing with 500 locations within 1s, 10x faster than current solvers for the same solution quality, enabling applications like real-time and interactive routing. EARLI can generalize to new data, as demonstrated on real e-commerce delivery data of a previously unseen city. Our hybrid framework presents a new way to combine reinforcement learning and genetic algorithms, paving the road for closer interdisciplinary collaboration between AI and optimization communities towards real-time optimization in diverse domains.
A Classification View on Meta Learning Bandits
Apr 06, 2025


Contextual multi-armed bandits are a popular choice to model sequential decision-making. E.g., in a healthcare application we may perform various tests to asses a patient condition (exploration) and then decide on the best treatment to give (exploitation). When humans design strategies, they aim for the exploration to be fast, since the patient's health is at stake, and easy to interpret for a physician overseeing the process. However, common bandit algorithms are nothing like that: The regret caused by exploration scales with $\sqrt{H}$ over $H$ rounds and decision strategies are based on opaque statistical considerations. In this paper, we use an original classification view to meta learn interpretable and fast exploration plans for a fixed collection of bandits $\mathbb{M}$. The plan is prescribed by an interpretable decision tree probing decisions' payoff to classify the test bandit. The test regret of the plan in the stochastic and contextual setting scales with $O (\lambda^{-2} C_{\lambda} (\mathbb{M}) \log^2 (MH))$, being $M$ the size of $\mathbb{M}$, $\lambda$ a separation parameter over the bandits, and $C_\lambda (\mathbb{M})$ a novel classification-coefficient that fundamentally links meta learning bandits with classification. Through a nearly matching lower bound, we show that $C_\lambda (\mathbb{M})$ inherently captures the complexity of the setting.